

On October 29, 2025, UNG Press Marketing and Content Manager Nicole Clifton and UNG student Joshua Lann presented at the Open Education Conference (OpenEd25) in Denver, Colorado. Informed by their work as UNG Press interns (Fall 2024) and student assistants (Spring 2025) converting Open Textbooks into audiobooks with AI assistance, their session, Innovating for All: AI-Powered Audiobook Creation in Open Textbook Publishing, highlighted how small academic publishers, faculty-led Open Educational Resources (OER) initiatives, and instructors can replicate their processes to expand OER accessibility without compromising quality or ethics. What follows are Clifton and Lann’s full presentation script and slides, shared with their permission via the UNG Press blog to further expand access to this information and promote OER accessibility.
Editor’s note: The following script guided Clifton and Lann’s presentation preparation but may not reflect the their October 29, 2025, OpenEd delivery verbatim.
Presentation

[Nicole Clifton] Hello! I’m Nicole Clifton, the Marketing and Content Manager for the University of North Georgia Press and a recent English graduate from the University of North Georgia with a focus in Writing and Publication, and a minor in communication.
[Joshua (Josh) Lann] And I’m Josh Lann, a senior in the same program, graduating this year with a minor in history.
[Clifton] Over the past academic year, we worked as student assistants at UNG Press, remediating two Open Textbooks from the press’s catalog into accessibility-focused audiobooks. We used AI to improve the efficiency of this process and began developing a Best Practices guide for others to replicate this work—especially other small publishers and OER advocates aiming to increase accessibility.
As many of you know, converting image- and terminology-heavy textbooks into audiobooks is exceptionally challenging. The two books we selected were specifically image- and vocabulary-dense to ensure the resulting workflow could handle even the most complex titles. Those OER were World History: Cultures, States and Societies to 1500, now available via Affordable Learning Georgia’s Manifold platform, and Introduction to Art: Design, Context, and Meaning, coming summer 2026.
[Lann] We leaned into AI tools, but human input and micromanagement remained at the core. Every step—from generating image descriptions to narration—required human oversight. Working with AI forced us to problem solve in innovative and out-of-the-box ways. The idea was to reduce the production load, especially for smaller teams that don’t have access to full recording studios or large budgets. AI helped us save time on repetitive tasks so we could focus on editorial decisions and accessibility improvements.
Process Walkthrough Part 1: Project Planning & Script Development
[Nicole] First, we’re going to walk through the earliest stages of our workflow: project planning and script development. Neither of us had prior experience with audiobook production or OER remediation, so we began by researching best practices for both—looking at accessibility guidance from organizations like DAISY Consortium and Accessible Publishing Canada, narration strategies for technical terminology, and ACX standards for audio quality and production guidelines.
With that foundation in place, we moved into script development, which included four main steps:
- Generating base scripts
- Creating and integrating image descriptions
- Addressing difficult-to-pronounce terms
- Sectioning scripts for narration and post-production
We used AI tools like ChatGPT-4o and Microsoft Copilot to streamline these steps in a secure, walled-garden environment. But, notably, human oversight remained essential—these tools accelerated repetitive work, but couldn’t execute tasks correctly 100% of the time without human oversight. Let’s dive further into how AI proved most effective in our four main stages of script development.

1. First, generating base scripts:
We used ChatGPT to extract and format text from textbook PDFs, one chapter per file. This was much faster than manual transcription, but left unchecked, the AI would start editing the text—aggressively. So we monitored extraction in real time, stopping and restarting when needed, which mitigated the issue.
2. Next, creating and integrating image descriptions:
For Introduction to Art, we generated extended image descriptions for nearly every one of its several hundred images—mostly complex artwork vital to experiencing the text’s full meaning—beginning each description with concise alt-text, and using clear “Start” and “End” cues for narration for later streamlining improving concision. ChatGPT 4o—recognized by the American Foundation for the Blind as a “game changer” for OCR in 2023–2024—proved especially helpful. We uploaded one image and caption at a time to minimize hallucinations, and reviewed each description against the original for accuracy. We then replaced in-line parenthetical figure references with these descriptions in our base scripts, ensuring comprehensiveness and relevancy for listeners and making the scripts easier to navigate for our human narrators and audio editors.
3. Now, onto addressing difficult terms:
Both books contained a high volume of technical and non-English terms. We built a pronunciation glossary with both IPA [International Phonetic Alphabet] and standard English phonetics, using ChatGPT to create those guides. Auditing ChatGPT’s generated phonetics revealed a final 75% first-attempt accuracy rate for generating pronunciation guides—but, only when provided with a customized phonetics pronunciation key. Before this, it had fallen just shy of 70%. Contrastingly, both our primary LLMs [Large Language Models] proved entirely ineffective at identifying difficult-to-pronounce terms or inserting phonetic guides into the scripts. We did those tasks manually, using Word’s Find & Replace tool for human narration, and custom rules in Speechify for AI narration—Josh will elaborate on that later.
4. Last but not least, sectioning scripts:
After developing scripts for each chapter, we divided each of those scripts into manageable segment—about 1,500 words each—for ease of narration and post-production. AI proved an excellent tool for expediting this process, though it took a while for us to get there. Ultimately, we discovered that Copilot was the most effective at document sectioning, word-count calculations, and formatting—but only when given an extremely specific, Python-based prompt. ChatGPT, meanwhile, proved excellent for troubleshooting the Python-based prompt given to Copilot, but not as efficient or as accurate as Copilot when it came to working within the Word Documents themselves, especially regarding creating awkward breaks, improperly calculating wordcount, or just going way off the beaten path with formatting. Though developing this prompt took time, it drastically improved the efficiency of executing this task long term, taking less than one minute to accurately divide entire documents into manageable sections. That sectioning proved vital for alleviating strain on human narrators’ voices and mitigating risks with corrupted work when working with AI narration—which Josh can expand upon.
Process Walkthrough Part 2: Audiobook Narration & Post-Production

[Josh] Once scripts were finalized with image descriptions and pronunciation guides, we brought them to life through narration. My focus was working with Speechify Studio, which allows you to generate AI voiceovers using either prebuilt narrators (often from iconic celebrities who gave their voice with written permission), or custom voice replicas — like the two we created from our coworkers’ samples (with their written permission, of course).
We used a 15–20 second voice sample of these coworkers, which Speechify turned into surprisingly accurate replicas. From there, we sectioned each script into 15-minute chunks and uploaded them into the platform. Each paragraph is separated into “blocks” so they can be individually edited or regenerated if the AI mispronounces something — which definitely happens.
To improve pacing, I manually inserted quarter-second pauses between sentences and one-second pauses between paragraphs or section titles. Otherwise, the AI has the tendency to combine sentences.
But the most time-consuming part? Listening. Each block had to be reviewed carefully — even if the AI got it right once, it might say the same word incorrectly a minute later. Or the AI will randomly stutter or become robotic. We relied heavily on our phonetic guides when we could and regenerated blocks until everything sounded consistent. Once the narration was finalized, I exported all the blocks and assembled them in the editing software called Audacity, where I cleaned up any pacing issues or digital glitches that slipped through. If needed, we could replace a faulty paragraph by copying and pasting an alternative take back into Speechify and then re-exporting the fix.
Discussion of Challenges & Solutions
[Josh] A major challenge I encountered was inconsistent AI pronunciation. Sometimes, there is only so much a phonetic guide can do. The replica will go haywire and pronounce the same word in very different (and often incorrect) ways. For the World History textbook, words such as “caliph” came out differently every time—it couldn’t decide if it wanted to be “cay-liff” or “cal-if.” Numbers were just as unpredictable—some were spelled out (like “one thousand nine hundred and seventy-five”), while others were concise (like “nineteen seventy-five”). My solution was to trick the AI into saying what I wanted by spelling out my own phonetics in odd and creative ways until the mechanism achieved what I directed it to do. Plenty of trial and error. The AI is stubborn, but can be controlled.
[Nicole] I encountered similar issues with pronunciation consistency when working with human and AI narration, both pre-programmed narrators and our individualized voice replicas. That’s what led me to integrate IPA phonetics into our glossary alongside our English-based ones and to create a pronunciation key. English orthography–as lovely and intuitive as it can be–is not always the most consistent. Even when working with a key, human and AI narrators varied their pronunciation of phonetics created with English spellings. IPA, on the other hand, is consistent, reliable, versatile—and great for when you’re working with languages with non-English etymologies, which we frequently were for these titles. The difficulty is in finding a human narrator or text-to-speech converter that can read IPA.
Granted, this entire premise may not be as much of an issue when working with textbooks carrying less-varied names and terms; however, we both viewed accurate, consistent pronunciation as vital—not only in terms of the finalized audiobook sounding polished, but also regarding supporting readers’ comprehension of the material.
And that was our entire goal with our projects: making these resources as accessible and as comprehensive as possible to as many learners as possible without compromising ethics or quality—while working within limited allocated resources. So, the UNG Press directed us toward AI tools and other university press’s AI practices and policies, which were still relatively new and not as thoroughly detailed yet at that point in time—which is why we also began creating a Best Practices guide detailing our workflow and case-study findings, now anticipated to release as a short-form monograph—or “brevigraph”—in 2026.
Discussion of Conclusions and Peer-Review
[Josh] To see if utilizing AI tools was an adequate solution, we made sure time track everything we could. For our study, we recorded chapters using actual human narration. We did this to test how far we can go given our limited budget when it came to sound and room equipment, as well as to note the quality and time differences.
[Nicole] We also conducted a peer review phase, with participants blindly grading audiobook samples made with AVR [Authorized Voice Replica] narration against samples made with human narration on factors such as accuracy, production quality, and engagement. Our grading system followed a scale of 1–5, with 1 reflecting the poorest rating in terms of accuracy, quality, and engagement and 5 reflecting the highest rating.
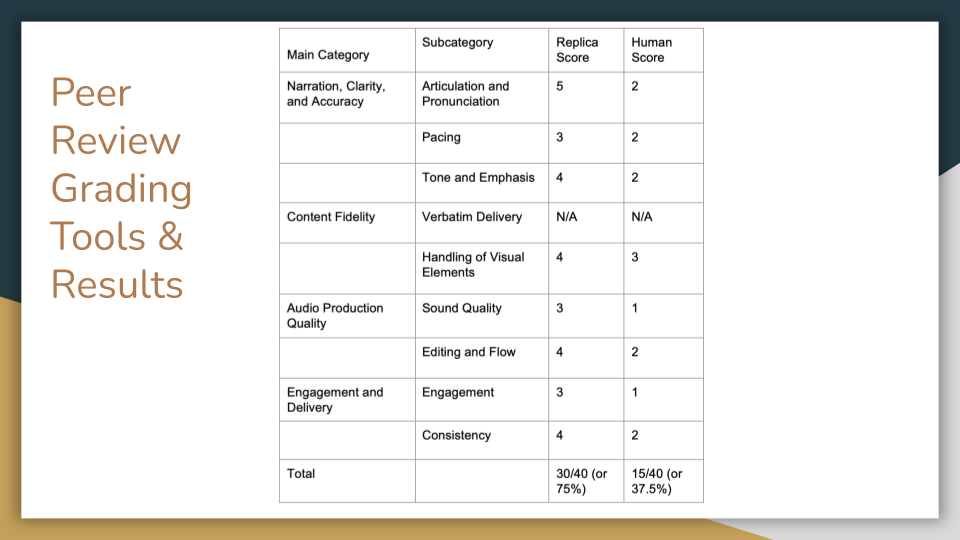
[Josh] This ended up being a really insightful contrast. Between human and AI narration, we concluded that, with the resources we had for legitimate audio recordings, the AI voice prevailed over the human one under most metrics.
[Nicole] Overall, the blind review granted a 75% rating to the AVR-narration sample, whereas it granted only a 37.5% rating to the human-narration sample. Notably, this was both of our first times creating an audiobook with either human or AI narration. However, the quality and efficiency differences measured between our AVR and human-narration case studies showed us how much potential AI-assisted workflows can offer for sustainable, replicable OER remediation enhancing accessibility. If we can do it as student assistants, anyone can.
[Josh] And that wraps up our presentation. Thank you so much for taking the time to see ours. There is much more to be said but we wanted to leave room for questions.
Q&A Segment (Highlights from October 29 OpenEd Presentation)

Editor’s note: The following depicts Clifton and Lann’s recollections of questions asked and their answers during their OpenEd25 presentation; not all questions and/or answers may be reflected verbatim.
Q1: How many people worked on this project [remediating UNG Press’s Open Textbooks into Audiobooks]?
A1 [Clifton & Lann]: The two of us essentially functioned as project managers. We received direct support and obtained narration and voice samples from the Press’s Director and Managing Editor, but it fell under our responsibilities to oversee and execute the creation of these audiobooks. So, most of the time, it was a total of two people working on creating those audiobooks.
Q2: Can you clarify the inputs and outputs involved with AI-assisted image description generation? Did you input the image, its caption, and its alt-text to generate an extended description?
A2 [Clifton]: Image-description generation was one of the trickiest stages for prompt refinement, but it drastically improved efficiency in script development. For Intro to Art, that involved uploading a screenshot of the image directly from the digital textbook that included its caption—specifying the artwork’s title and artist’s name, if applicable—within the frame. Uploading this to the Press’s walled-garden ChatGPT environment along with a detailed prompt clarifying what details to include or omit—informed by accessibility best practices outlined by DAISY Consortium and AccessiblePublishing.ca—and formatting specifications to input within the audiobook scripts generating alt-text and extended descriptions for uploaded images. Human oversight was needed to ensure accuracy, especially with more detailed, complex, or abstract artwork.
Q3: How can we be informed when the book covering best practices for AI in OER audiobook production will be released. Where can we access it [the brevigraph]?
A3 [Clifton]: The best practices will be published openly through the University of North Georgia Press. All their open publications are available on their website, ungpressbooks.com. You can sign up for their newsletter to stay up-to-date. You can follow my colleague [Lann] and I on LinkedIn for updates as well.
Learn More
Clifton and Lann’s presentation demonstrated that with creativity, careful human oversight, and ethical AI use, even small presses with limited resources can produce accessible, engaging audiobooks from Open Textbooks without compromising ethics or quality.
Read Lann’s article about presenting at OpenEd25 for a behind-the-scenes look at his experiences and takeaways from the conference: Presenting at OpenEd25: Reflections from a UNG Press Student Assistant.
Sign up for the UNG Press newsletter to be the first to know when the brevigraph covering best practices in AI-assisted OER audiobook creation is available: UNG Press Newsletter Signup.
Leave a Reply